
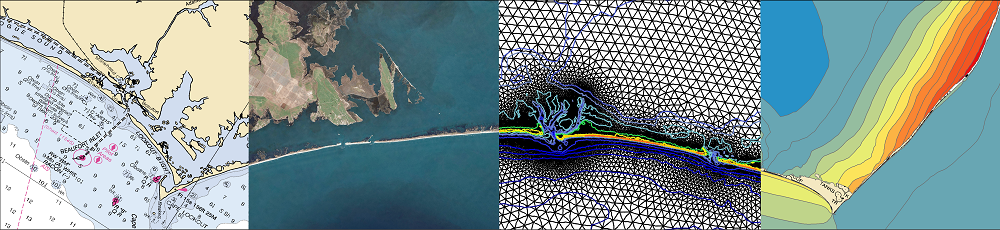
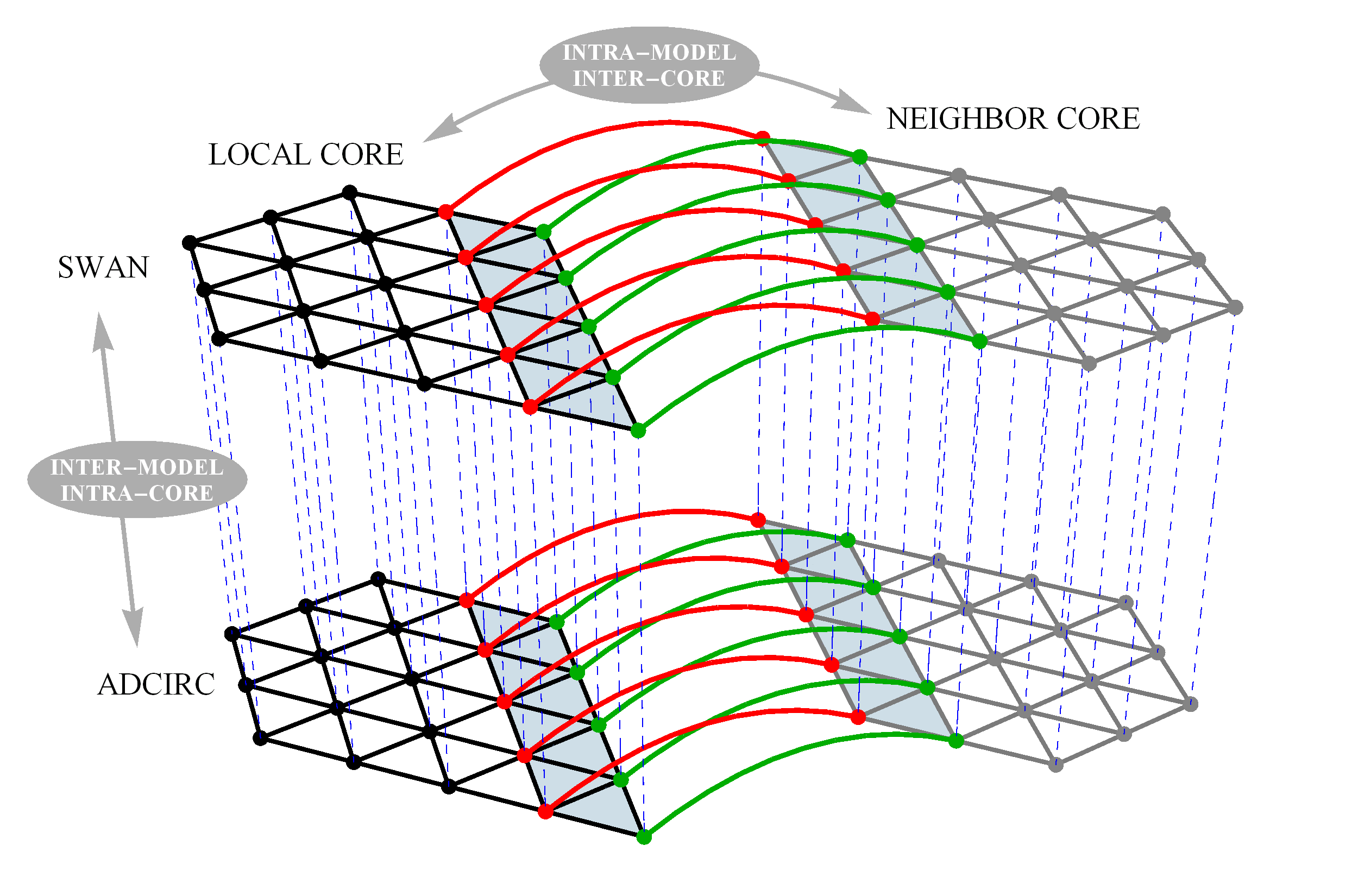
If you want the coupled model, then please follow the link at the bottom of the ADCIRC website to request the latest release version. Here is an instruction manual on how to compile and run SWAN+ADCIRC.
- Compile padcirc successfully on your system. This compilation is performed typically by navigating to the
worksubdirectory and typing:
make padcircThe parallel version of the unstructured SWAN model utilizes the parallel infrastructure from ADCIRC. Specifically, it needs the SIZES and MESSENGER object files. So those need to be compiled before the coupled model is compiled.
- Compile the parallel version of the unstructured SWAN model successfully on your system. The only reason to do this is to make sure that you have the correct setting of compiler flags. The SWAN source code is located in a
swansubdirectory on the same level assrcandwork. In that directory, first do a combination of:
make clean
make clobberto delete any stray files from a previous compilation. Then type:
make configto have SWAN attempt to create a file (
macros.inc) with compiler flags for your system. You might double-check that everything in that file seems reasonable. In particular, please be sure to add the line:O_DIR = ../work/odir4/somewhere in that file. Then type:
make punswanto make the parallel, unstructured version of SWAN. It will follow the SWAN convention of assigning the name
swan.exeto the executable.SWAN is set up in much the same way as ADCIRC, with dedicated compiler flags for certain architectures (in the
platform.plfile), but they do not have compiler flags for everything. You might be able to use their commands and have everything work out of the box, or you might need to develop your own set of compiler flags. Either way, make sure that you can compile the unstructured SWAN itself before trying to compile the coupled model.At the end of this process, you should have a
macros.incfile that contains the compiler flags for your system. Our ADCIRCmakefilewill include that file during the compilation of the coupled model.UPDATED 2010/03/24: The parallel version of the unstructured SWAN model assumes the user has the MPI modules loaded already, and it utilizes them with lines like:
USE MPIIf you receive errors about this line, then you’ll need to tell the compiler to include the MPI libraries as it does its thing. You can do this by adding a flag to the last line of the
macros.incfile. The flag is-impiand it is added to theswchline:swch = -impi ...This flag enables sections of the code that tell the compiler to include the MPI libraries. Note that this is similar in effect to not using the
HAVE_MPI_MODcompiler flag with ADCIRC. - To compile the coupled SWAN+ADCIRC model, you first need to remove the files in the
swansubdirectory that were created during the compilation of the parallel SWAN model. You can do this by typing:
make clean
make clobberto remove the stray files. Then navigate to the
worksubdirectory and type:make adcswanor type:
make padcswanto compile the serial or parallel version of the coupled model, respectively. Both SWAN and ADCIRC will be compiled into the same executable.
(A possible problem here is that ADCIRC uses double-precision reals, while SWAN uses single-precision. I have encountered this bug on several platforms, and I think I have fixed it throughout the code. But this is a good issue to examine if your machine chokes at this stage.)
UPDATED 2010/03/24: The parallel version of the unstructured SWAN model assumes the user has the MPI modules loaded already, and it utilizes them with lines like:
USE MPIIf you receive errors about this line, then you’ll need to tell the compiler to include the MPI libraries as it does its thing. You can do this by adding a flag to the ADCIRC
makefilefile. The flag is-impiand it is added to the following line:@perl ../swan/switch.pl -impi ...This flag enables sections of the code that tell the compiler to include the MPI libraries. Note that this is similar in effect to not using the
HAVE_MPI_MODcompiler flag with ADCIRC. - You can also compile a version of adcprep for the coupled model. This version will adjust the boundary information at the end of the
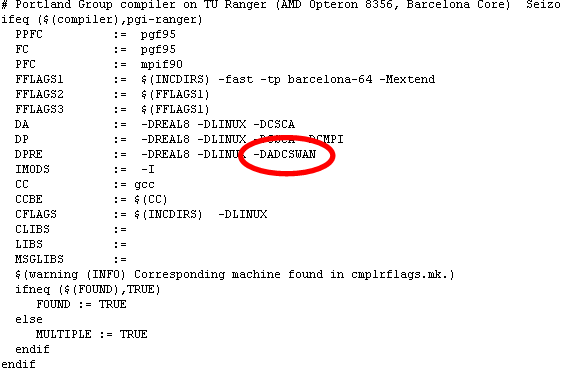
fort.14grid file to make it compatible with SWAN, and it will copy the SWAN control file (which is typically calledfort.26) into the local PE sub-directories. This version is necessary for running the coupled model. However, you can also use this version of adcprep for non-coupled ADCIRC runs, too. (Just type ‘skip’ when it asks for the name of the SWAN control file.Simply add the-DADCSWANflag to theDPREline for your system in thecmplrflags.mkfile:
- To run the coupled model, you will need to make two changes to the ADCIRC
fort.15model parameters file. (Note that you do not need to make any changes to thefort.14grid file.) In the parameters file, setNWS= +/- 3XX. The coupling to SWAN is enabled when the hundreds digit ofNWSis 3; this will tell ADCIRC to pull the radiation stress gradients from SWAN. Also, on theWTIMINCline, setRSTIMINCequal to the SWAN time step. Then ADCIRC will pull new radiation stress gradients from SWAN at the end of each SWAN time step. We have been using a 600-second time step for SWAN, and that seems to work well. So the changes to thefort.15file for a hot-started run using OWI-formatted winds and a wave coupling interval of 600 seconds would look like:

- SWAN requires a control file, which we will call the
fort.26file. More information about this control file can be obtained from the SWAN User Manual. We use some commands inside that input file to send the ADCIRC wind speeds, water levels and currents to SWAN. It also requires a driver file calledswaninit. If you want to see examples of these two files, then please contact me, and I will send you my latest versions.
- Use the new executable to run the coupled model in much the same way you would run the serial or parallel ADCIRC. On my system, this can be done by typing something similar to:
mpirun -np 512 ./padcswan -W 10Note that the
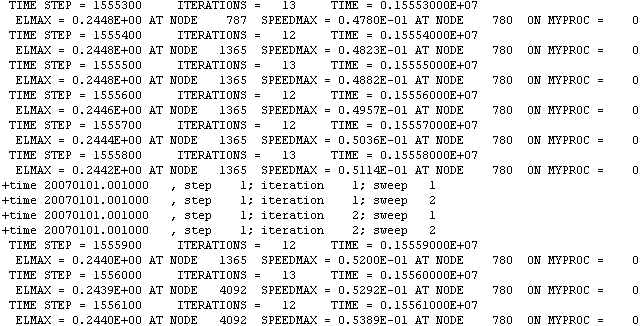
-Wflag controls the dedicated writer cores, as described below. In my experience, the SWAN half of the coupling takes roughly the same amount of time as the ADCIRC half, (depending on the coupling interval and SWAN time step, of course,) so the overall run time will roughly double. Although SWAN is unconditionally stable and can take a much larger time step than ADCIRC, it has to solve for many more unknowns per time step.As SWAN+ADCIRC runs, you should see the time-stepping information for both models. It should look something like:
- If you have turned on the output of the wind pressures and speeds (to the unit 73 and 74 files) in the
fort.15file, then you will also receive several output files containing variables related to SWAN and the coupling. These files are:rads.64… radiation stress gradientsswan_HS.63… significant wave heightsswan_DIR.63… mean wave directionsswan_TMM10.63… mean wave periodsswan_TPS.63… peak wave periods
Note that the quantities in capital letters correspond to SWAN output variables that are documented at the SWAN User Manual. You can also use the standard output commands in the SWAN control file, but they will write local output files to the PE directories and in a format that is new to ADCIRC users. I thought it would be useful to write these four wave quantities to global files with an ADCIRC-like format.
In this case, SWAN+ADCIRC will be writing global output to a bunch of files: the five files named above, plus the unit 63, 64, 73 and 74 files. That amount of output is sure to swamp the buffer of even the most sophisticated machine. I highly recommend using the dedicated writer cores. The idea is to set aside several cores for dedicated file output, thus freeing the remaining cores to continue with the computations. For example, you might run adcprep to decompose the global input files into 502 PE subdirectories. But the run itself would go on 512 cores, and the writer cores would be activated with the
-Wflag at run-time:mpirun -np 512 ./padcswan -W 10We have noticed significant speed-ups when using the dedicated writer cores, and run-times can be cut in half or more on some machines. You want to set aside at least one writer core for each global output file. For SWAN+ADCIRC with all of the global output files being written, that means you need at least 10 nine writer cores.
UPDATED 2010/02/09: In recent versions of SWAN+ADCIRC, I have disabled the output of the mean wave periods TM01 and TM02 to global files. We use the TMM10 periods, so it seemed redundant to create separate, large files with the TM01 and TM02 periods. However, the output of these periods (or other SWAN parameters) can be enabled again if necessary; please contact me to find out how.
I think that is all. We have experienced some problems with our SL15 mesh in the southern Gulf, Caribbean Sea and Atlantic Ocean. If the bathymetry is not smooth, then the wave refraction inside SWAN will experience problems. We have worked around this issue by turning off the refraction in the subdomains outside southern Louisiana. This requires editing the fort.26 files after they have been copied by adcprep into the local PE subdirectories. I have a small FORTRAN program that will do this; please let me know if you want it. Moving forward, we need to design meshes that are appropriate for both SWAN and ADCIRC.
I hope this helps. Please let me know if you have any questions.